

In this tutorial, we dive deep into the world of data migration, focusing on the best practices for effectively migrating your data between infrastructure providers, specifically considering the use case for when you manage users' data in a community environment which is being provided by a third party.
In the previous tutorial, How to easily migrate data from getSocial with Amity Migration tool, we explored the key features and limitations of this tool. Its main functionality is to help migrate most of the social experience data so that key relevant aspects from users’ interactions and details can be effectively managed. Nevertheless, you can build your own tool that can be customised to a further extent considering your data requirements. Let’s begin with these steps of best practices for effectively managing data migration!
Map your own data extraction points
When embarking on the journey of data extraction, it’s crucial to map your own data extraction points meticulously. Each data source is unique, and identifying the specific points where your valuable information resides is the first step to successful data extraction. Depending on your provider, you may encounter a diverse array of APIs that hold the key to accessing the data you seek. Therefore, take the time to explore and understand the intricacies of these APIs, as they will serve as the gateway to unlocking the treasure trove of data awaiting extraction.
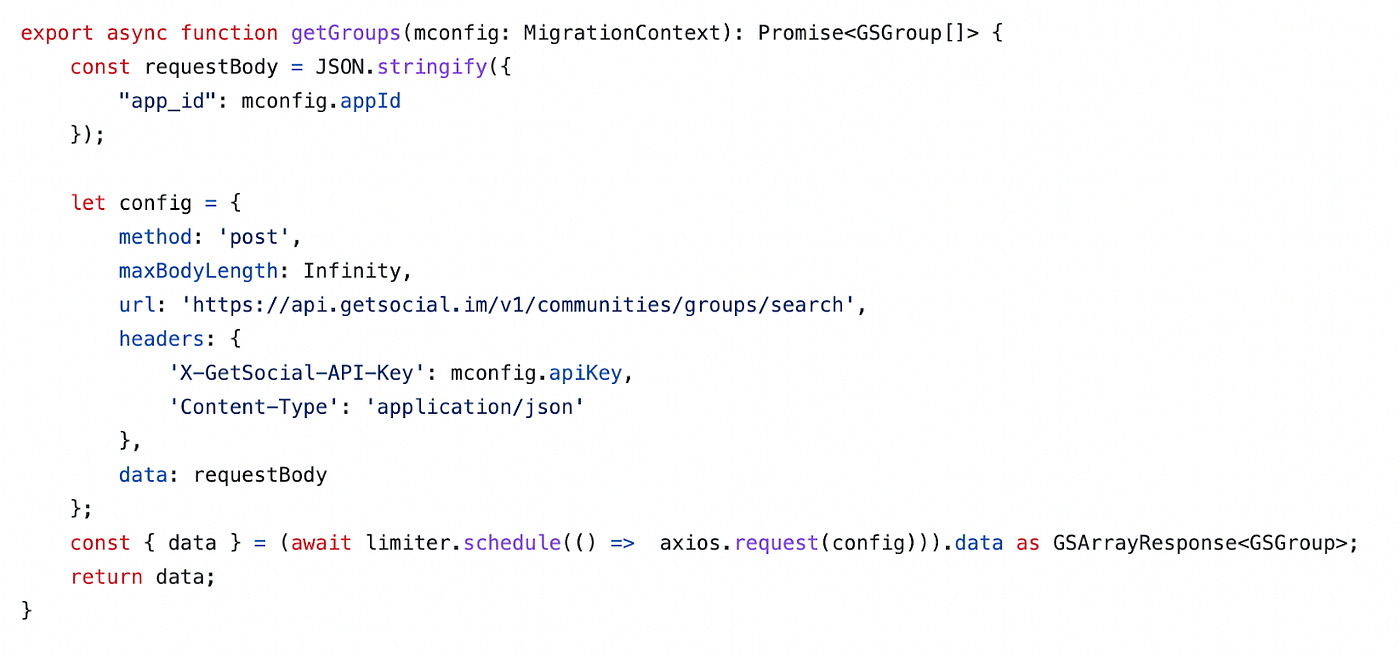
Having as example Amity’s Migrator Tool for GetSocial, GetSocial.ts file contains the diverse set of data structures that will be extracted from GetSocial. These details were mapped from GetSocial’s API Documentation, where the diverse available endpoints were evaluated and taken into consideration. Here you can see a quick view of a code snippet used for collecting that data endpoint:
Classify data’s relevance according to your use case
Once you have diligently mapped your data extraction points and gained access to the diverse APIs, the next crucial step in the data migration process is to classify the data’s relevance according to your specific use case. Not all data may be equally essential for your intended objectives, and determining the significance of each dataset ensures that you focus your efforts on extracting and migrating the most valuable information.
In the previous example, this practice is exemplified by employing the GetSocial.ts file, which contains a curated set of data structures to be extracted from the GetSocial platform. This meticulous curation is based on an evaluation of the diverse available endpoints present in GetSocial’s API Documentation. By examining and understanding each endpoint, developers can make informed decisions about which data is pertinent to their migration objectives, streamlining the process, and maximising the utility of the extracted data and timelines.
Map the entry points from the new provider or infrastructure
Once you have successfully classified the relevant data for your migration goals, the next critical step is to map the entry points from the new provider or infrastructure. By diligently exploring the API documentation of the new provider or infrastructure, developers can identify the specific endpoints and data structures required for migrating the extracted data. This meticulous mapping allows for a targeted approach, enabling the migration tool to precisely migrate the necessary information. By leveraging the knowledge from this mapping process, you can streamline the data migration, minimising the risk of data loss or inaccuracies, and optimizing the overall efficiency of the migration.
For reference purposes, Amity’s Migrator Tool for GetSocial relies on the AmitySocialCloud.ts file as the key location where data migration entry points are located. Within this file, the migration tool finds the selected and relevant entry points to access and interact with Amity’s APIs, which act as the gateway to the new community environment’s data. As in step 1, Amity’s API documentation was reviewed to understand which endpoints will accomplish the migration use case and what type of data structure they support, so adaptations can be considered in case they are necessary. The following is another example of code snippet used for this purpose:

Develop the migration tool
After the previous steps of mapping data extraction points, classifying data relevance, and identifying entry points from the new provider or infrastructure, the stage is set to embark on the development of the migration tool. The script acts as a bridge, seamlessly calling the mapped endpoints for data extraction and subsequently transferring the extracted data to the designated receiver endpoints. The script should be meticulously designed to handle data transformation, ensuring compatibility between the source and destination formats. Moreover, it should incorporate error-handling mechanisms to address any potential issues during the migration. As the backbone of the migration tool, the script needs to be highly efficient, reliable, and scalable to accommodate varying data volumes and migration complexities.
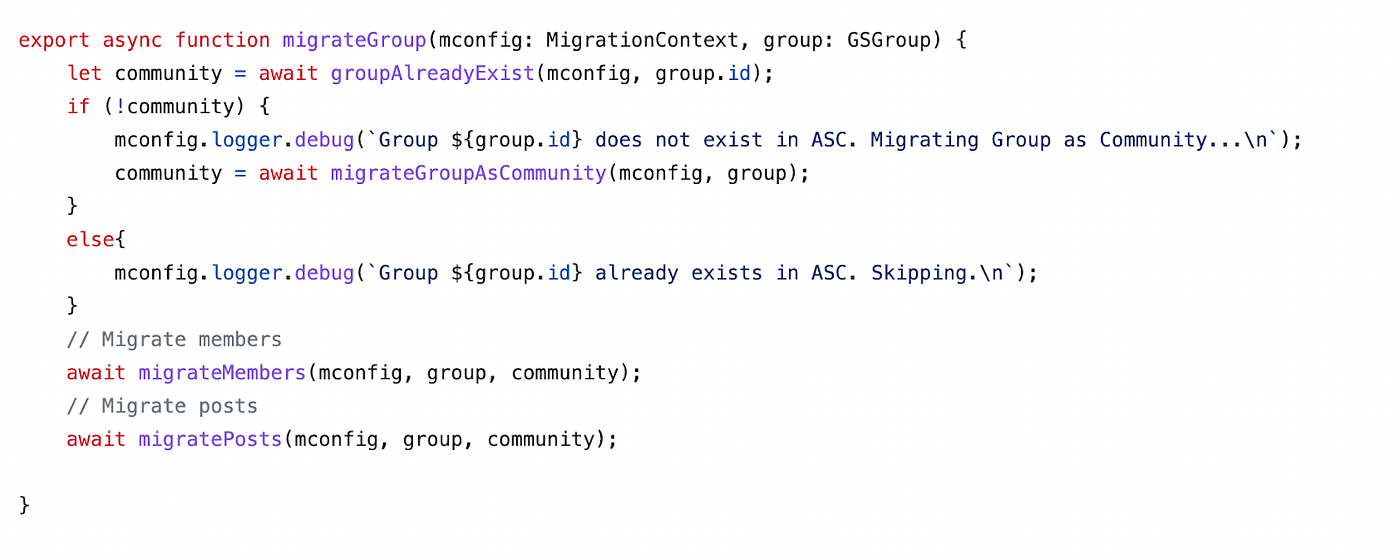
Taking into consideration the previous use case, the migrateGroup() function, fueled by a MigrationContext, a GSGroup, and an ASCCommunity as parameters, expertly handles the migration of the selected group, effectively transforming it into a community and returning the migrated community as the result.
With the foundation laid for migrating the group, the next critical step is to address the migration of posts, comments, and reactions that are associated with the group. Amity’s Migrator Tool demonstrates the way forward with the migratePosts() function, which works in tandem with a MigrationContext, a GSGroup, and an ASCCommunity as parameters. The migratePosts() function is designed to loop through the posts within the group, efficiently extracting and migrating each post alongside their relevant comments and reactions.
Test in trial environments, fix and migrate
Before fully deploying the migration tool, it is essential to thoroughly test its capabilities and performance in trial environments. Testing in controlled settings enables developers to identify and address any potential issues or unforeseen challenges that may arise during the migration process. By subjecting the tool to trial runs, data engineers can simulate real-world scenarios, ensuring that the tool effectively handles various data volumes and complexities.
After conducting comprehensive testing in trial environments, the final phase of the migration process involves fixing any identified issues and executing the actual data migration. The insights gained from the trial runs enable developers to fine-tune the migration tool, addressing and rectifying any bugs, performance bottlenecks, or data integrity concerns. The culmination of this marks the successful completion of the data migration process.
Final Thoughts
In conclusion, mastering data migration emerges as a fundamental aspect of modern data management, providing businesses with the vital ability to navigate the ever-evolving digital landscape with efficiency.
By comprehending and implementing best data migration practices, encompassing mapping data extraction points, classifying data relevance, and identifying entry points from the new provider, organizations can ensure a seamless transition of their invaluable information.
The illustrative example of Amity’s Migrator Tool for GetSocial exemplifies the significance of crafting a tailored migration tool that perfectly aligns with specific data requirements.